

Lorsque j’ai voulu utiliser une fonctionnalité de versioning lors du développement de mon site web, j’ai naturellement utilisé Gitlab. Mais Gitlab ne se contente pas de proposer simplement cette fonction, c’est une plateforme DevOps complète. En l’utilisant, pourquoi ne pas essayer d’utiliser un peu d’automatisation même si vous êtes seul à travailler sur votre projet.
Donc, comme mon projet est petit et, comme indiqué, je suis seul dessus, cet article doit être pris comme une légère introduction au fonctionnement de Gitlab avec son Gitlab Runner. Je ne vais pas montrer comment faire de la compilation ou même des tests. Nous allons simplement passer en revue la façon dont Gitlab utilise un fichier d’orchestration spécifique qui est automatiquement exécuté lorsque vous faites un git push vers une branche spécifique.
Comment ça marche ?
Gitlab, comme son nom l’indique, est une plateforme basée sur le protocole Git. Mais c’est bien plus que ça. C’est un système de développement collaboratif complet permettant aux équipes de travailler ensemble sur plusieurs projets. Il se distingue par l’intégration de fonctionnalités CI/CD.

Qu’est-ce que le CI/CD ?
Cela signifie intégration continue et livraison/déploiement continu (c’est soit la livraison, soit le déploiement, pas les deux car ils sont opposés comme vous allez le comprendre).
L’intégration continue est la partie que vous connaissez peut-être déjà. C’est l’organisation en branches de codes dans lesquelles les développeurs valident leurs modifications et les fusionnent pour procéder à un commit complet sur la branche principale. C’est vraiment ce que Git apporte sur la table en plus du versioning mais automatisé.
La livraison continue est le concept de compilation et de test automatiques à chaque commit sur la branche principale. Une fois les tests terminés et les modifications approuvées, le logiciel est prêt à être publié. Mais cela ne signifie pas qu’il est réellement publié, il est simplement considéré comme prêt.
Le déploiement continu est comme la livraison mais, comme son nom l’indique, le logiciel est automatiquement déployé (ce que la livraison ne fait pas). L’ancienne révision est supprimée et la nouvelle mise en place. Ce type d’organisation va vraiment de pair avec les micro-services via le conteneur.
Pour ce que nous souhaitons dans ce petit projet, c’est simplement un déploiement continu que nous allons mettre en place. En effet, nous souhaitons simplement pousser les fichiers de notre site Web vers le SFTP automatiquement lorsque nous validons les modifications. Pas de test, pas de compilation, pas de fusion, etc…
En pratique
La façon dont Gitlab exécute toute cette automatisation est via un Gitlab Runner. Ce runner n’est qu’une autre machine sur laquelle des commandes sont exécutées. Il peut s’agir d’un ordinateur à part entière ou simplement d’un conteneur, cela n’a pas vraiment d’importance tant que le système a le logiciel Gitlab Runner chargé dessus et connecté à l’instance principale de Gitlab.
Les runners sont de trois types :
- Spécifique
- Groupe
- Partagé
Je pense que les noms sont évidents, mais expliquons-les quand même. Un runner spécifique sera dédié à un projet spécifique. C’est idéal pour un projet actif et gourmand en calcul. Les runners de groupe et partagés sont partagés entre les projets, la différence entre les deux est que les runners de groupe exécuteront des tâches pour un groupe de projets tandis que les runners partagés exécuteront des tâches pour tous les projets configurés pour permettre leur utilisation.
Pour envoyer ces commandes au runner, Gitlab exécute des tâches via des pipelines. Un job n’est qu’une instance d’exécution d’un fichier de configuration qui contient une recette qui indique au runner ce qu’il doit faire. Ce fichier de configuration a pour nom de fichier .gitlab-ci.yml et doit se trouver à la racine de votre projet git. Comme vous l’avez peut-être deviné, le fichier est écrit en YAML. Le pipeline est l’ensemble complet des tâches créées par un fichier spécifique.
Parce que nous voulons quelque chose de simple, je vais simplement mettre en place un runner partagé. Je n’ai pas beaucoup de projets en cours sur mon Gitlab et je suis seul pour travailler dessus donc c’est largement suffisant pour moi.
Configuration du Gitlab Runner
Tout d’abord, vous devez installer le logiciel Gitlab Runner. Je ne vais pas vous expliquer comment procéder, car la documentation Gitlab le fait déjà bien. Je vous encourage donc à le vérifier. Dans mon cas, j’ai installé Docker avant le runner, car je l’utiliserai dans mon automatisation. Je l’ai installé sur un conteneur LXC non privilégié sur mon serveur Proxmox, car c’était la solution la plus rapide et la plus simple pour moi.
Pendant le processus d’installation, une liste d’exécuteurs vous sera présentée et il vous sera demandé lequel choisir. Si vous souhaitez utiliser ma configuration comme base, vous devrez installer Docker et le choisir lorsque cela vous sera demandé.
Est-il installé pour vous ? Bien, il est maintenant temps d’aller dans le panneau d’administration de votre instance Gitlab principale. Pour y accéder, allez dans Menu > Admin

Vous devez être connecté avec un utilisateur disposant des droits d’administrateur sur votre Gitlab pour que l’option soit disponible
Une fois là-bas, sous Overview, il y a la page d’administration des Runners.
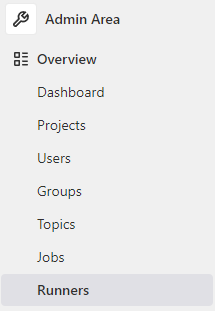
Cliquez sur Register an instance runner, puis sur Show runner installation and registration instructions.
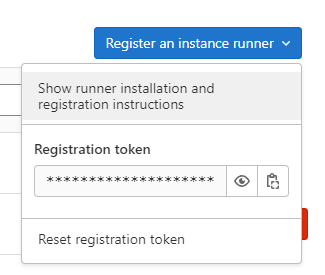
Une fenêtre contextuelle Install a runner s’affichera. Vous pourrez récupérer les informations nécessaires à l’enregistrement de votre runner nouvellement installé.
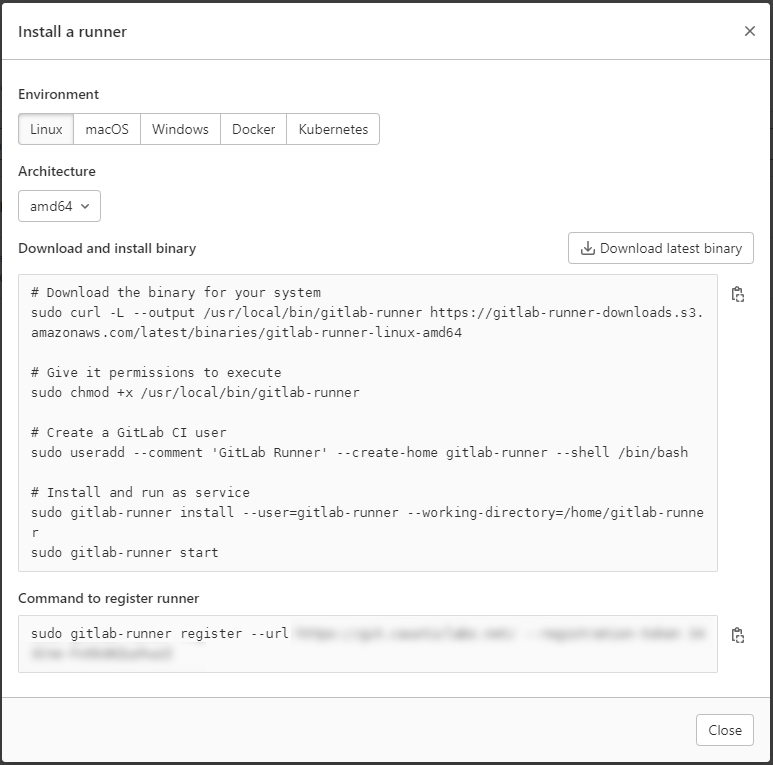
Si vous avez déjà installé le logiciel Gitlab Runner comme je vous l’ai dit, il vous suffit de regarder le bon environnement (bien sûr) et de copier la commande en bas. Cette commande doit être exécutée sur la machine du coureur elle-même.
Une fois terminé, il apparaîtra dans votre instance Gitlab avec le statut en ligne. Par défaut, ils sont configurés comme partagés, nous n’avons donc plus rien à faire de ce côté-là.
Configuration de CI/CD
Avant de commencer
Nous devons d’abord activer le projet pour utiliser le runner. Pour le configurer, votre utilisateur doit avoir le rôle de mainteneur ou de propriétaire sur le projet cible, les autres rôles ne peuvent pas modifier les paramètres d’un projet.
Alors, allez dans votre instance Gitlab, ouvrez votre projet puis allez dans Settings > CI/CD. Il y a une section appelée Runners qui est réduite par défaut. Cliquez sur Expand. Assurez-vous, dans la colonne de droite, sous la section Shared runners, que l’option Enable Shared runners for this project est activée (comme dans la capture d’écran ci-dessous).
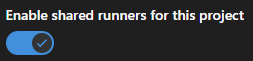
Maintenant, les bases sont posées pour utiliser cette fonction.
Création du fichier de configuration
Ce fichier contient toutes les commandes du runner. Il est écrit en YAML et utilise une structure spécifique. Si vous avez déjà joué avec Docker, vous serez dans un environnement familier. Surtout parce que nous utilisons Docker dans cet exemple.
Vous devez le créer dans le dossier racine de votre projet git. Le nom du fichier doit être .gitlab-ci.yml. Maintenant, chaque fois que vous envoyez votre commit, Gitlab analysera le fichier et agira en conséquence de ce qu’il contient.
Envoi de fichiers via SFTP
Ce que nous voulons faire est vraiment simple par rapport à ce dont un studio de développement aurait besoin. Mais ce sera une bonne introduction à la façon d’utiliser ce fichier avec certaines variables d’environnement définies via Gitlab.
Comme nous utilisons Docker, nous pouvons considérer ce fichier comme un mélange d’un fichier Docker Compose et d’un Dockerfile. De cette façon, nous pouvons rassembler les informations nécessaires pour créer ce fichier avec succès.
Premièrement, quelle image de base utiliser ? Je vais utiliser Alpine Linux, une petite distribution légère optimisée pour être utilisée dans ce type d’environnement.
Deuxièmement, quelles commandes voulons-nous exécuter pour transférer les fichiers ? La méthode la plus simple consiste à utiliser un logiciel appelant LFTP qui peut gérer tout le transfert via une seule ligne de commande. Pour le protocole, nous utiliserons SFTP car il utilise SSH qui est déjà disponible sur mon serveur Web de test et je ne veux pas mettre en place un serveur FTP complet juste pour les tests. Parfois, le fournisseur d’hébergement peut limiter l’accès à SFTP uniquement, ce qui pourrait vous être utile.
L’ensemble du processus de choix et d’itération des tests jusqu’à la création finale du script complet a été assez bien couvert par ‘t is goud, je vous encourage à le consulter.
Commands
apk add --no-cache openssh lftp mkdir /root/.ssh chmod 700 /root/.ssh touch /root/.ssh/known_hosts chmod 600 /root/.ssh/known_hosts ssh-keyscan -p $SFTP_PORT -H $SFTP_HOST >> /root/.ssh/known_hosts lftp -e "mirror --delete --parallel=5 --transfer-all --reverse -X .* --verbose website/ /var/www/html; bye" -u $SFTP_USER,$SFTP_PASSWORD sftp://$SFTP_HOST -p $SFTP_PORT
Comme vous pouvez le voir, on utilise des variables, on verra plus tard comment les créer.
La première ligne est une commande utilisée pour installer OpenSSH afin d’obtenir la compatibilité SFTP sur l’extrémité locale et LFTP pour des raisons évidentes.
Les 4 commandes suivantes sont utilisées pour créer le fichier know_hosts car ssh-keyscan ne peut pas le créer tout seul dans ce contexte.
SSH-Keyscan est utilisé pour collecter les informations du serveur ssh et les placer dans le fichier known_hosts. Désormais, il n’est plus nécessaire d’approuver la clé lors de la première connexion au serveur ssh.
LFTP effectuera tous les transferts. Il utilise différents paramètres :
- -e » « Commande(s) à exécuter – Elles sont placées entre les guillemets
- mirror Mettre en miroir le dossier distant sur le dossier local
- –delete Supprimer les fichiers et dossiers de la destination qui ne sont pas présents dans la source
- –parallel=n N nombre de transferts à exécuter en parallèle
- –transfer-all Forcer le transfert de tous les fichiers même s’ils existent déjà dans la destination
- –reverse Inverser les dossiers source et de destination – le dossier distant est maintenant la destination
- -X Ignorer les fichiers correspondants
- –verbose Afficher toutes les actions exécutées
- source/folder destination/folder Évidemment, l’emplacement des dossiers source et de destination
- bye Quitter la commande
- -u USER,PWD Spécifie l’utilisateur et le mot de passe pour se connecter
- sftp://host Adresse SFTP à laquelle se connecter
- -p PORT Port à utiliser pour la connexion
Fichier complet
Décomposons le dossier complet :
image: alpine:latest
before_script:
– apk add –no-cache openssh lftp
build:
script:
– mkdir /root/.ssh
– chmod 700 /root/.ssh
– touch /root/.ssh/known_hosts
– chmod 600 /root/.ssh/known_hosts
– ssh-keyscan -p $SFTP_PORT -H $SFTP_HOST >> /root/.ssh/known_hosts
– lftp -e « mirror –delete –parallel=5 –transfer-all –reverse -X .* –verbose website/ /var/www/html; bye » -u $SFTP_USER,$SFTP_PASSWORD sftp://$SFTP_HOST -p $SFTP_PORT
only:
– main
Comme vous pouvez le voir, les commandes sont divisées en deux sections et quelques autres lignes sont ajoutées.
La première ligne est l’image que nous avons choisie. J’utilise alpine avec la balise :latest. Vous devez utiliser une version fixe en production.
N’UTILISEZ PAS LA DERNIÈRE EN PRODUCTION !!! JUSTE POUR TESTER
La section before_script contient la commande pour préparer l’image avant son utilisation. Bien sûr, la partie installation du logiciel s’y fait.
La section build contient ce que je décrirais comme la partie informatiquement intéressante. Elle s’appelle build car c’est dans cette partie que vous feriez le processus de compilation.
Elle contient la section script, c’est assez évident ce que fait cette partie, ce sont toutes les commandes pour construire le logiciel.
Elle contient également la section only. Vous y définirez dans quelle branche le commit entraînera l’exécution du job. Dans cet exemple, à chaque commit sur la branche principale, le job est exécuté.
Variables
Maintenant, passons à la dernière partie pour finaliser notre configuration de Gitlab. Les variables !
Donc, allez dans votre instance Gitlab, ouvrez votre projet puis allez dans Paramètres > CI/CD. Il y a une section appelée Variables qui est réduite par défaut. Cliquez sur Développer.
Il suffit de cliquer sur Ajouter des variables, de saisir le nom de la variable dans Clé puis de mettre les données que nous voulons transmettre dans Valeur et enfin de cliquer sur Ajouter une variable.
Le nom dans la clé est celui qui sera utilisé dans le script précédé de $
Cochez Cacher la variable pour la variable mot de passe
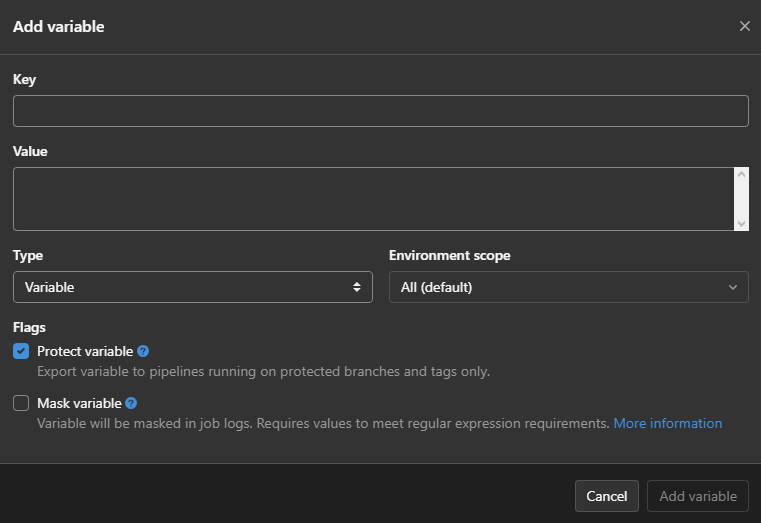
Dans cet exemple, nous avons besoin de :
- l’adresse du serveur (SFTP_HOST)
- le port utilisé par SFTP (SFTP_PORT)
- l’utilisateur utilisé pour la connexion (SFTP_USER)
- le mot de passe de l’utilisateur (SFTP_PASSWORD)

Commit !
Maintenant, tout est prêt. Lors du prochain commit sur la branche appropriée, vous pourrez voir les tâches en cours d’exécution dans la page CI/CD de votre projet.
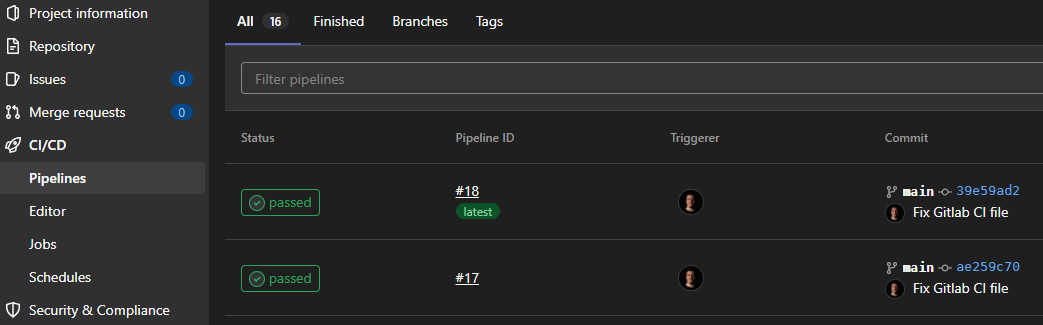
Si vous cliquez sur l’état du pipeline, vous pourrez obtenir plus d’informations.
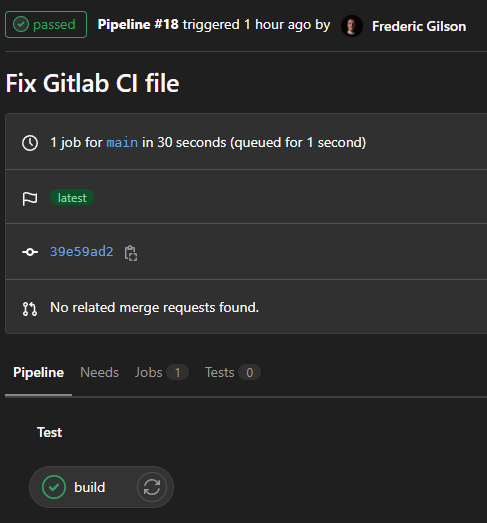
Ensuite, si vous cliquez sur le bouton du bas nommé d’après la section dans notre fichier yaml, vous obtiendrez l’output.
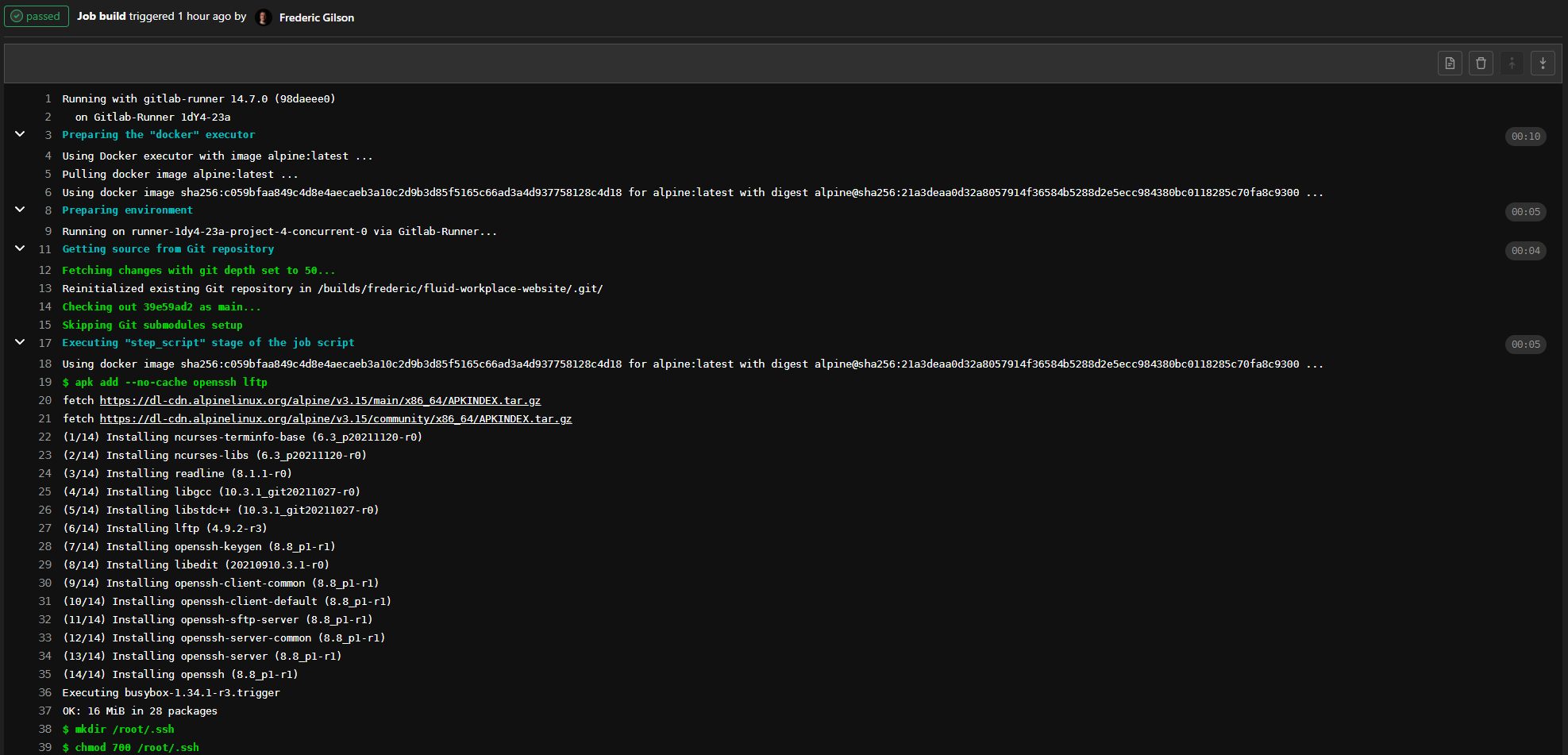
Voilà ! Si vous avez des questions ou des commentaires, n’hésitez pas à me contacter. Il est maintenant temps de commencer à développer avec un peu moins de tracas !